Was ist der Unterschied von Pihole zu einem Adblocker?
Warum einen Raspberry Pi mit etwas ausstatten, das ein Adblocker im Browser auf den ersten Blick auch kann? Weil Adblocker-Plugins etwas anders funktionieren und aufgerufene Websites erst blocken, sobald sie euren PC, Mac oder das Smartphone erreicht haben. Pihole hat einen anderen Ansatz, denn es blockt Tracker, Viren-verseuchte Websites und Werbung auf DNS-Ebene.
Das heißt, dass das Pihole quasi alles ausfiltert, bevor es an die Geräte im Netzwerk ausgeliefert wird. Wie ein Sieb, das zwischen eurem Router und allen Geräten im Netzwerk arbeitet. Und es bringt den Vorteil mit, dass diese Geräte auch in den nativen Apps werbefrei sind – und nicht nur mit Plugins oder speziellen Apps. Ich blicke in deine Richtung, iPhone.
Weniger Tracking, mehr Speed
Weniger Tracker bedeuten auch gleichzeitig mehr Privatsphäre, denn die eingebauten Filter sorgen dafür, dass deutlich weniger Informationen über euer Surfverhalten gesammelt werden können. Pihole ist zwar kein Tails oder Tor, das euren Traffic über fünf Millionen Proxies und dann noch mal zur Venus schickt, blockt aber sehr viele Anbieter und gefährliche Seiten.
Weniger Werbung und weniger Gefunke von Trackern und Analytics-Anbietern bedeutet zudem weniger Traffic und schnellere Ladezeiten von Websites und Apps. Na, überzeugt? Das alles braucht ihr für die Einrichtung.
Diese Hardware brauchst du für den Raspberry Pi mit Pihole
- Einen Raspberry Pi – im Grunde tut es jeder Raspberry, auch der Raspberry Pi 1 oder Zero. Wir empfehlen euch jedoch einen Raspberry Pi 3 und aufwärts, um die Weboberfläche vom Pihole flott nutzen zu können.
- Ein Netzteil – oder einen USB-Anschluss mit 2A-Output oder mehr.
- Eine Micro-SD-Karte und einen SD-Adapter, der Karten meistens beiliegt.
- Optional: Ein Gehäuse für den Raspberry Pi.
- Optional: Einen Hoodie, da ihr ein paar einfache Shell-Befehle kopieren werdet und dabei aussehen müsst, wie ein Hacker.
Software für Pihole
- Balenaetcher – oder Rufus oder Unetbootin.
- Raspberry Pi OS Lite – das offizielle Betriebssystem für den Raspberry Pi.
Vorbereitung der SD-Karte
- Ladet euch im ersten Schritt Balenaetcher (oder eine der oben erwähnten Alternativen) herunter und installiert das Tool. Balenaetcher braucht ihr, um das Betriebssystem für den Raspberry Pi auf der SD-Karte zu „installieren“. Das Image öffnen und die Dateien kopieren funktioniert übrigens nicht, da eine Partitionstabelle auf die Micro-SD-Karte geschrieben werden muss.
- Raspberry Pi OS findet ihr hier, wobei ihr für das Pihole nur die „Lite“-Version braucht. Bei der Veröffentlichung dieses Artikels ist das Raspberry Pi OS (32-bit) Lite (basierend auf Debian Buster). Ihr könnt aber auch die 64-Bit-Variante installieren oder die Version mit einer Desktopumgebung, falls ihr den Raspberry Pi mit Pihole noch für andere Dinge verwenden wollt.
- Startet Balenaetcher, wählt die heruntergeladene und entpackte Datei und dann die Micro-SD-Karte aus, die nun mit oder ohne Adapter in eurem PC stecken sollte. Checkt bitte vorher, dass ihr die richtige Micro-SD-Karte und nicht eine externe Festplatte oder den USB-Stick auswählt (den mit dem geheimen Ordner, den Mutti niemals sehen sollte).
- Balenaetcher schreibt das Raspberry Pi OS auf die SD-Karte, und somit wäre das gute Stück dann auch schon bereit für den Einsatz. Steckt die Karte in euren Raspberry und stöpselt ihn mit einem HDMI- und am besten einem Netzwerkkabel verbunden an die Strombuchse. Ihr braucht zudem eine Tastatur mit Bluetooth-Adapter oder ganz oldschool eine mit Kabel.
Voreinstellungen des Raspberry Pi OS
Nachdem der Raspberry Pi gebootet hat (was ein wenig nach „Matrix“ aussieht), loggt ihr euch mit folgenden Logindaten und Passwort ein:
pi
raspberry
(beziehungsweise „raspberrz“, da die Tastatur noch auf Englisch eingestellt ist)
Ich bin zwar kein Hellseher, nehme aber an, dass ihr mit hoher Wahrscheinlichkeit eine deutsche Tastatur nutzt. Damit das auch der Raspberry weiß, gebt ihr im Terminal ein:
sudo raspi-config
In dem Konfigurationstool hüpft ihr zu Punkt 4 (Localisation Options) und stellt im nächsten Schritt die Locale unter I1 auf Deutsch (DE), die Timezone (I2) auf Berlin, das Keyboard Layout (I3) auf Deutsch (DE) und WLAN Country (I4) ebenfalls auf DE. Die Punkte wählt ihr mit der Space-Taste an oder ab und wechselt mit Tab auf „Select“ beziehungsweise „Back“. Nach etwas Gerödel verlasst ihr das Menü über „Finish“ und startet den Raspberry am besten neu, mit:
sudo reboot
Nach dem Neustart ändert ihr zunächst das Passwort, damit Mr. Robot nicht so einfach Zugriff auf euren Raspberry Pi hat. Loggt euch ein (diesmal mit hoffentlich deutschem Tastaturlayout) und gebt ein:
passwd
Gebt euer aktuelles Passwort ein (raspberry) und dann euer neues, das ihr am besten in einem Passwortmanager speichert. Um das Betriebssystem auf den neuesten Stand zu bringen, führen wir ein Update durch, mit:
sudo apt update && sudo apt -y upgrade && sudo apt-get -y dist-upgrade && sudo apt -y autoremove && sudo apt -y autoclean && sync && sudo reboot
Nach dem Neustart installiert ihr nun Pihole und macht euch erstmal zum root, da Pihole bestimmte Rechte für die Installation braucht:
sudo passwd root
Vergebt jetzt ein temporäres Passwort und loggt euch als root ein, mit:
su -
Deutsche Tastatur:
- sudo raspi-config
- Punkt 4 Localisation Options
- l3 Change Keyboard Layout
- PC generic de 105 tecles (intl.)
- Runtergehen auf „Andere“
- Das Wort Duits suchen und bestätigen
- Dann nach oben und DUITS auswählen
- und dann geht es komischerweise wie gewohnt weiter
Die Installation von Pihole auf dem Raspberry Pi
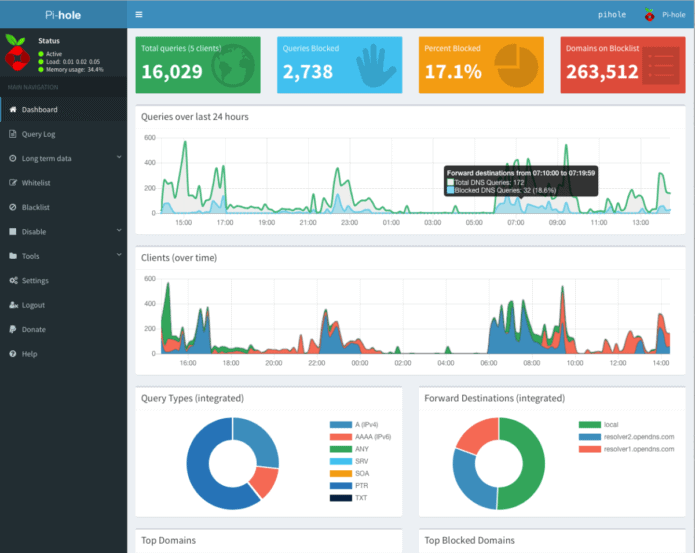
Falls ihr nicht wisst, welche IP euer Pihole hat, findet ihr es so raus und notiert es am besten:
hostname -I
(das ist ein großes I, wie „Ihhh“, kein L)
Jetzt installiert ihr das Pihole über das Skript:
curl -sSL https://install.pi-hole.net | bash
Sollte das nicht funktionieren, weil curl fehlt, könnt ihr auch Folgendes tun:
wget -O basic-install.sh https://install.pi-hole.net
sudo bash basic-install.sh
Bei Problemen findet ihr weitere Infos zur Installation auf der GitHub-Seite von Pihole. Das Skript installiert und arbeitet ein bisschen vor sich hin und wird euch zwischendurch einige Fragen stellen, die ihr wie folgt, beantworten könnt:
Select Upstream DNS Provider: Cloudflare oder Google oder einer eurer Wahl.
Select Lists: Wählt hier einfach alle Listen aus.
Select Protocols: IPv4 und/oder IPv6, falls ihr IPv6 nutzt.
Do you want to use your current network settings as a static address: Gebt hier die IP-Adresse des Raspberry Pi ein, die euer Router zugewiesen hat (beziehungsweise Enter), und wählt den Router als Gateway aus – meist 192.168.0.1, aber prüft es zur Sicherheit nochmal in den Einstellungen eures Routers.
Do you wish to install the web admin interface: Ja, denn hier nehmt ihr nachher Einstellungen vor und seht, was das Pihole alles filtert.
Do you wish to install the web server (lighttpd): Ja, denn ohne läuft auch die Weboberfläche nicht oder ihr müsst euch den Server anders zusammenfrickeln.
Do you want to log queries: Ja, sofern ihr die Zugriffe in Logdateien speichern wollt.
Select a privacy mode for FTL: Je nachdem, ob ihr ein öffentliches Netzwerk betreibt oder die Anfragen schlicht und einfach komplett anonymisieren wollt (hallo DSGVO), könnt ihr hier einstellen, was genau geloggt wird.
Nach der Installation zeigt euch das Skript die Adresse des Pihole als IPv4 und/oder IPv6 sowie das Passwort für die Weboberfläche an. Loggt euch wieder als root aus und auch ein Neustart kann nicht schaden:
exit
sudo passwd -dl root
sudo reboot
Pihole als DNS-Server des Routers eintragen
Im Grunde könnt ihr den Raspberry nun an seinen Zielort verfrachten. Er braucht nur noch Strom und ein Netzwerkkabel zu eurem Router. Das Pihole funktioniert im Grunde auch per WLAN, sofern es nicht der ganz alte Raspberry Pi 1 ist. Für eine stabile Verbindung, und um etwas Frickelei zu vermeiden, solltet ihr aber ein Netzwerkkabel nutzen. Wer den Raspberry Pi übrigens nicht kennt: Das Teil hat leider keinen An- oder Aus-Schalter. Ihr macht ihn an, wenn ihr das USB-Kabel anstöpselt und fahrt ihn am besten herunter mit:
sudo shutdown now
Dann könnt ihr ihn vom Strom trennen und wieder anklemmen, wenn ihr ihn einschalten wollt. Im Idealfall wird er aber die ganze Zeit durchlaufen und Trackinganfragen, Werbung und anderen Firlefanz auf DNS-Ebene blocken. Damit das funktioniert, müsst ihr das in einem letzten Schritt eurem Router mitteilen.
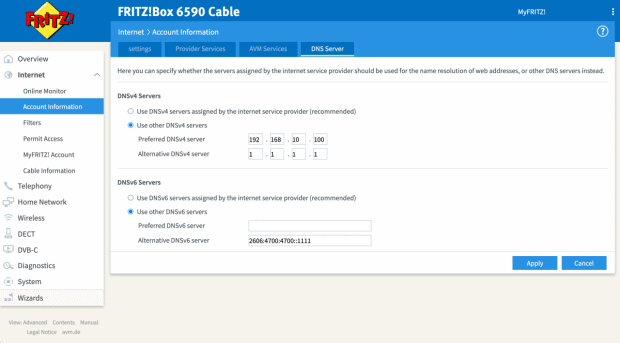
Pihole müsst ihr im Backend der Fritzbox als DNS-Server eintragen. Hier unterscheiden sich die Modelle bei ihrer Weboberfläche natürlich. Bei der Fritzbox findet ihr die Einstellung unter Internet > Zugangsdaten > DNS-Server.
Hier gebt ihr die IPv4- und/oder die IPv6-Adresse eures Pihole ein. Als Alternative empfiehlt sich noch ein zweiter DNS-Server, falls ihr den Raspberry mal wechseln, aber dennoch weiter Internet haben wollt. Hier bieten sich Cloudflare (1.1.1.1) oder Googles DNS-Server (8.8.8.8) an, aber ihr könnt natürlich nehmen, was ihr wollt.
Die Weboberfläche und weitere Einstellungen
Im Grunde sollte alles out-of-the-box funktionieren. Ihr könnt euch die Weboberfläche vom Pihole ansehen, indem ihr die IP-Adresse im Browser angebt und ein „/admin/“ anhängt, zum Beispiel:
http://192.168.0.10/admin/
Loggt euch mit dem Passwort aus der Installation ein und ihr könnt euch auf dem Dashboard ansehen, wie viele Anfragen vom Pihole geblockt worden sind, welche Domains und Tracker das waren und so weiter. Wenn ihr die Listen aktuell halten wollt, könnt ihr unter dem Punkt Tools > Update Gravity auf Update klicken.
Eine Allow-Liste findet ihr ebenfalls im Menü links und ihr werdet sie das eine oder andere Mal brauchen, denn manchmal blockt Pihole relativ harmlose Werbetracker oder versaut euch Links in Newslettern, da diese meist über Tracking-Tools laufen. Setzt die entsprechenden Domains dann einfach auf die Liste oder schaltet Pihole kurzzeitig mit einem Klick auf Disable aus und wählt, für wie lange er ausbleiben soll.
Wer möchte, kann das Pihole auch als DHCP-Server nutzen, DNSSEC aktivieren, als rekursiven DNS-Server mit Unbound nutzen, weitere Adblock-Listen hinzufügen oder die Allow-Lists automatisch updaten lassen. Auf die gehört übrigens auch www.t3n.de – ist ja klar. Wie ihr das alles anstellt, erfahrt ihr hier:
- Unbound als rekursiven DNS-Server einrichten
- Massenimport von Adblock-Listen mit pihole5-list-tool
- Tipps für Whitelisting unkritischer Tools und Services
- Pi-Hole mit OpenVPN und DNSCrypt basteln
Als kleiner Tipp: Wenn das Blocken mal nicht direkt funktioniert, wartet ein paar Minuten, bis euer Netzwerk das Pihole als DNS-Server „vermittelt“ hat. Oder startet euer Gerät ein Mal neu. Das gleiche gilt auch, wenn ihr das Pihole im Menü kurzzeitig ausschaltet, denn ein paar Sekunden lang wird es Tracker immer noch blocken.
Neue Ad-Block Filterlisten in Pi-hole einbinden

Standardmäßig enthält Pihole 5.0 aktuell 7 Filterlisten zum Blocken von Domains bzw. Webseiten. Diese ermöglichen Pihole das Filtern von unerwünschten Inhalten wie z.B. Werbebannern oder unerwünschten Scripten. Durch das Hinzufügen weiterer Filterlisten lässt sich die Zahl der unerwünschten Domains sehr einfach erhöhen. Wir wollen euch heute zeigen, wie ihr euren Pi-hole noch besser im Ad-Blocking machen könnt.

Filterlisten gibt es wie Sand am Meer. Wichtig ist, dass diese Listen gepflegt werden, denn die Listen werden nicht nur einmal in Pihole eingebunden, sondern regelmäßig auf Änderungen geprüft. Wir haben für euch ein paar Listen bzw. Webseiten zusammengetragen:
- 1,3 Millionen Webseiten Blockliste
- wichtige Listen auf siehe https://firebog.net/
- Filter-Lists.com – sehr große Sammlung an AdBlock-Listen (ca. 150)
- Adblock Plus 2.0 (EasyList) – Wird von vielen Browser-Adblockern genutzt
- Firebog Blocklist Collection – Viele gepflegte Adblock-Listen
- Unsere aktuelle Block-Liste für youtube-Werbung (vom 02.02.2020):
https://www.sunshine.it/blacklist.txt
for blocklists i’m using
https://raw.githubusercontent.com/StevenBlack/hosts/master/hosts https://mirror1.malwaredomains.com/files/justdomains http://sysctl.org/cameleon/hosts https://zeustracker.abuse.ch/blocklist.php?download=domainblocklist https://s3.amazonaws.com/lists.disconnect.me/simple_tracking.txt https://s3.amazonaws.com/lists.disconnect.me/simple_ad.txt https://hosts-file.net/ad_servers.txt https://raw.githubusercontent.com/HenningVanRaumle/pihole-ytadblock/master/ytadblock.txt https://github.com/anudeepND/youtubeadsblacklist/blob/master/domainlist.txt https://v.firebog.net/hosts/lists.php?type=tick
for blacklists i’m using
ad.doubleclick.net clients6.google.com googleads.g.doubleclick.net i1.ytimg.com pagead2.googlesyndication.com pubads.g.doubleclick.net r1—sn-vgqsen7z.googlevideo.com r1.sn-vgqsen7z.googlevideo.com r17—sn-vgqsenes.googlevideo.com r2—sn-vgqs7n7k.googlevideo.com r20—sn-vgqs7ne7.googlevideo.com r20.sn-vgqs7ne7.googlevideo.com r4—sn-vgqs7nez.googlevideo.com r4.sn-vgqs7nez.googlevideo.com securepubads.g.doubleclick.net static.doubleclick.net www.youtube-nocookie.com
I’ve had decent success with this regex
^r[0-9]*([-]{1,3}|.)sn-[a-z0-9]{4,}-[a-z0-9]{4,}\.googlevideo
It’s not perfect, but does block about 80% of the ads that play during streaming, but only about 40% of the ads that play before the video begins.
Einbinden neuer Filterlisten in Pi-Hole
Ab der Version 5 von Pi-Hole befindet sich die Verwaltung der Filterlisten im Gruppen-Management der Software. Ihr könnt mehrere Gruppen definieren, die dann auf unterschiedliche Blocklisten zugreifen können.
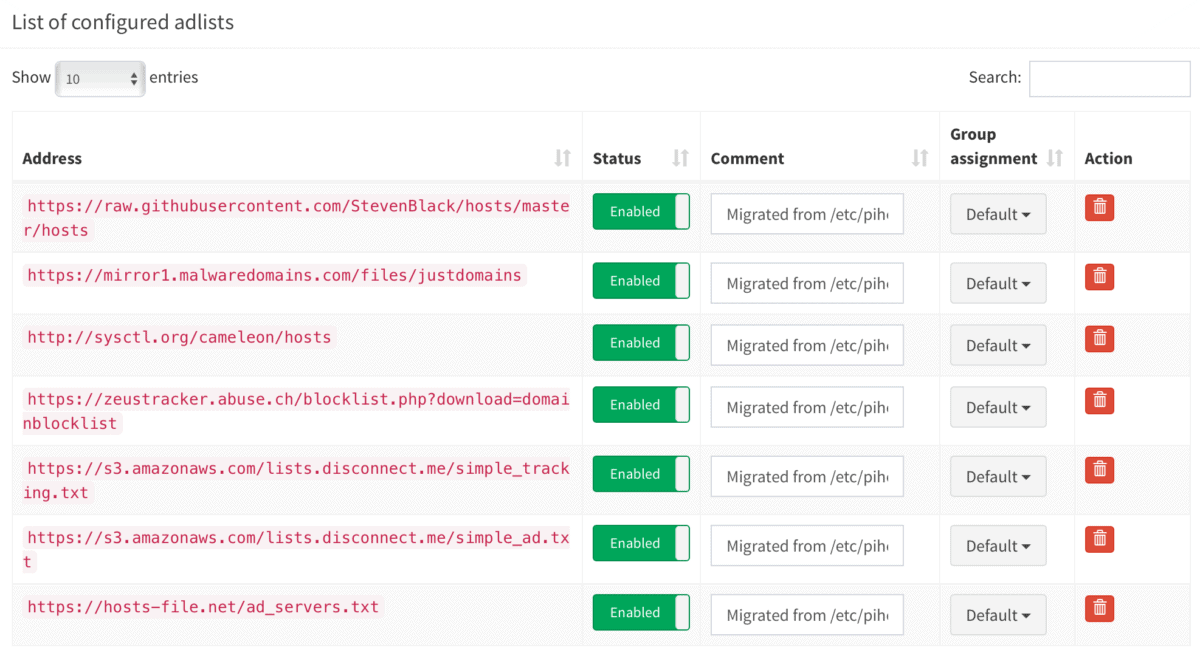


pihole5-list-tool
Installing Python packages
sudo apt update
sudo apt install python3-picamera
sudo apt install python3-pip
installation
If you don’t sudo pip3 install, things won’t work – possibly in a very confusing way. Definitely on Raspbian 10, so probably before that.
$ sudo pip3 install pihole5-list-tool --upgrade
usage / running
Simply run:
$ sudo pihole5-list-tool
Finishing up
After adding lists, they must be loaded by running:
$ pihole -gallowlists
Currently the only source for maintained whitelists is anudeepND’s allowlist. They are presented as:
Allowlist Only – Domains that are safe to allow i.e does not contain any tracking or
advertising sites. This fixes many problems like YouTube watch history, videos on news sites and so on.Allowlist+Optional – These are needed depending on the service you use. They may contain some
tracking sites but sometimes it's necessary to add bad domains to make a few services to work.Allowlist+Referral – People who use services like Slickdeals and Fatwallet need a few sites
(most of them are either trackers or ads) to be whitelisted to work properly. This contains some analytics and ad serving sites like doubleclick.net and others. If you don't know what these services are, stay away from this list. Domains that are safe to whitelist i.e does not contain any tracking or advertising sites. This fixes many problems like YouTube watch history, videos on news sites and so on.
ad/blocklists
Currently the only source for maintained blocklists is firebog.net
- Non-crossed lists: For when someone is usually around to whitelist falsely blocked sites
- Ticked lists: For when installing Pi-hole where no one will be whitelisting falsely blocked sites
- All lists: For those who will always be around to whitelist falsely blocked sites
Zusätzliche Whitelists
Gibt es, um mal welche zu nennen:
Aber die Ersteller/Verwalter von Blocklists sollten Einträge aus solchen Whitelists eigentlich bereits aus ihren Listen entfernt haben.
IP-Adresse oder sonstige Netzwerkeinstellungen ändern
Reconfigure pi hole via command line: pihole -r
You can also change ip address in
/etc/pihole/setupVars.conf
Updating
Updating is as simple as running the following command:
pihole -up
How do I set or reset the Web interface Password?
The Web interface password needs to be reset via the command line on your Pi-hole. This can be done locally or over SSH. You will use the pihole command to do this:
pihole -a -p
You will be prompted for the new password. If you enter an empty password, the password requirement will be removed from the web interface.



